
Table of Contents
GPT 4o
Context: Open AI launched the new flagship AI model GPT-4o.
About GPT-4o
- It is capable of accepting audio and visual inputs and generating outputs almost flawlessly.
- The ‘o’ in GPT-4o stands for “omni,” indicating its ability to handle multimodal inputs through text, audio, and images, unlike earlier versions which only handled text inputs.
- Performance and Features
- Response Time:
- Audio input response time: 232 milliseconds.
- Average response time: 320 milliseconds.
- Uses fillers or repeats part of the question to manage latency.
- Integrated Neural Network: Unlike previous models that used separate processes for voice-to-text conversion and operations, GPT-4o uses the same neural network for these tasks, enabling faster responses and deeper insights.
- Response Time:
- Technology Behind GPT-4o:
- Large Language Models (LLMs):
- LLMs are the core technology of AI chatbots like GPT-4o.
- They involve feeding vast amounts of data into models to enable them to learn and understand patterns in language and information.
- Large Language Models (LLMs):
- Applications:
- Caricature creation from a photo.
- 3D logo creation and manipulation.
- Generating meeting notes from audio recordings.
- Designing cartoon characters and stylized movie posters.
- Assessing interview readiness and making jokes based on visual cues.
- Setting up games, assisting with maths problems, recognizing objects in Spanish, and expressing sarcasm.
- Limitations:
- No Video Generation: Despite its visual understanding capabilities, GPT-4o cannot generate videos, such as movie trailers.
- Initial Errors: Demonstrations included some errors, such as producing gibberish text in a crime movie-style poster, later refined but still somewhat raw.
Examples, Case Studies and Data
- Disaster Management (GS- 2): In 2023, India experienced over 528,000 internal displacements due to floods, storms, earthquakes, and other disasters, a significant decrease from approximately 2.5 million displacements in 2022.
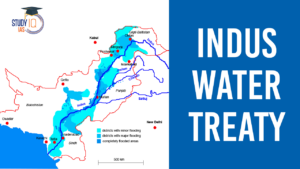 Indus Water Treaty 1960 Suspended by Ind...
Indus Water Treaty 1960 Suspended by Ind...
 5 Years of SVAMITVA Scheme and Its Benef...
5 Years of SVAMITVA Scheme and Its Benef...
 Places in News for UPSC 2025 for Prelims...
Places in News for UPSC 2025 for Prelims...





















